
The next big model that OpenAI that's the successor to GPT-4, whatever its called.
apparently the market disagrees but my understanding of the situation is that gpt-4o was likely the base model for o1, and that o3 and gpt-5 were further finetunes of o1? (also seems possible that gpt-4.1 was the base for o3 i suppose.) so this seems extremely likely to me?
the original gpt-4 was an undertrained 1.8T MoE, and there doesn't seem to be a huge advantage to doing RLVR with a larger model (see: Claude 4.5 Sonnet outperforming Claude 4.1 Opus on various SWE tasks), so it would greatly surprise me if GPT-5 was larger than GPT-4. and the inference api costs for GPT-5 are much lower than the equivalents for models like GPT-4 and GPT-4.5, which supports this hypothesis
i suppose this is likely to take a stupidly long time to resolve, but it seems very mispriced to me
@Bayesian No, it's not crazy. OpenAI demonstrated an extremely granular MoE architecture with gpt-oss-120B, which was trained for less than $4 million. Based on that architecture, it's very likely they can easily train a scaled up variant of the model with 1,750B parameters for about $100 million. And it's very unlikely they spent only $100 million on training GPT-5.
@bh Possible, but not certain. Details about the model might leak. There are also some methods to estimate the number of parameters. It's just the model speed that is not a good indicator.
@Bayesian OpenAI very likely serves trillions of tokens per day with GPT-5 (see Google below with 30T tokens per day), which even at the lowest end of plausible estimations (3T tokens per day) amounts to inference costs of least 10 millions dollars per day. Even if they would hypothetically plan on keeping GPT-5 for only three months before fully deprecating it, doesn't it seem weird that they wouldn't or couldn't spend an additional 100 million in training for reducing operating costs by more than 1 million dollars per day?
https://techcrunch.com/2025/07/23/googles-ai-overviews-have-2b-monthly-users-ai-mode-100m-in-the-us-and-india

even at the lowest end of plausible estimations (3T tokens per day) amounts to inference costs of least 10 millions dollars per day
Not true. a LOT of google's token use for instance likely comes from very small models where almost all the tokens "processed" are as input and cached and are being processed by tiny models, like when reading people's emails or google docs or whatever else, within google products.
Even if they would hypothetically plan on keeping GPT-5 for only three months before fully deprecating it, doesn't it seem weird that they wouldn't or couldn't spend an additional 100 million in training for reducing operating costs by more than 1 million dollars per day?
Definitely not weird. they spend training as long as the training gets them useful gains, but it's not easy to use up enough gains bc data-wise they are limited. and if they "better use the data" by scaling the model up, it makes inference more expensive in a way that is kind of non obvious to model and idk what the like strategically best curve is like
so yeah i suspect gpt-5 has around as many parameters as gpt-4 and would lean toward fewer but i don't actually know
Not true. a LOT of google's token use for instance likely comes from very small models where almost all the tokens "processed" are as input and cached and are being processed by tiny models, like when reading people's emails or google docs or whatever else, within google products.
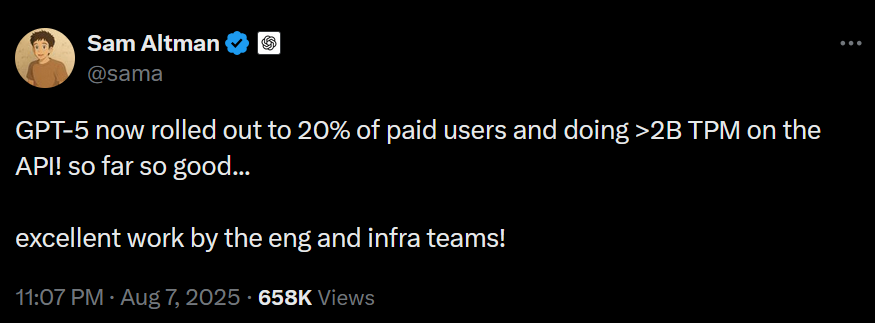
That's ~3T tokens per day even at 20% rollout. That includes input and cached tokens, but GPT-5-thinking produces so many output tokens, that they probably have the largest share by far.
Definitely not weird. they spend training as long as the training gets them useful gains, but it's not easy to use up enough gains bc data-wise they are limited. and if they "better use the data" by scaling the model up, it makes inference more expensive in a way that is kind of non obvious to model and idk what the like strategically best curve is like

That's exactly what you'd expect, if you spent more compute on training: less output tokens for the same results. A rough approximation is that you can substitute test-time compute with training compute, which would imply 2x to 5x more training than o3. With the dense model scaling laws that would result in only 30%-50% less throughput, but GPT-5 is almost certainly not dense. For sparse models the throughput loss can be negligible or they can be even faster when sparser than the baseline (which is probably the case for GPT-5. Either that, or they use a lower quantization, perhaps as low as 1.58bit / parameter). As for the training data, yes, OpenAI seems to have run out of sufficiently high quality human data a few months ago, but I haven't heard from any major AI company that they encountered significant problems in training with synthetic data.
In any case, here's some independent estimation (https://www.theguardian.com/technology/2025/aug/09/open-ai-chat-gpt5-energy-use):

Please clarify "The next big model that OpenAI that's the successor to GPT-4, whatever its called." Is this market about GPT-4.5 (just released, plausible claimant to that description) or GPT-5 (speculated to be released in ~two months, the model named in the market title)?
Edit: Oh, market creator's account is deleted. What now?
Which GPT-4 and which GPT-5? Initial release of both?
It seems that OpenAI sometimes makes models with different parameter counts available as different versions of the same external name. For example, it looks like GPT-4o just shrunk.