

The total power consumption could be estimated to be around 50-60 million kWh for training GPT-4.
1/10th of this energy = 5-6 million kWh
1/100th of this energy = 0.5-0.6 million kWh
See calculations below:
Related
🏅 Top traders
| # | Name | Total profit |
|---|---|---|
| 1 | Ṁ1,931 | |
| 2 | Ṁ100 | |
| 3 | Ṁ96 | |
| 4 | Ṁ92 | |
| 5 | Ṁ45 |
@mods Resolves as YES (creator deleted). OpenAI just introduced gpt-oss-20b, a model that it trained with far less than 1/100th of the energy used to train GPT-4, while being far superior to GPT-4 (see https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf). Details:
Training gpt-oss-20b required about 0,21 million H100-hours (page 5 of the model card, see screenshot below).

The market's creator used 8way systems as a baseline, meaning training required 26,250 DGX H800-hours running at a maximum of 10.2kw (https://viperatech.com/product/nvidia-dgx-h800-640gb-sxm5-2tb). The total power consumed by the servers was thus 0.26775 million kWh. Multiplication with the creator's PUE of 1.18 yields a total of 0.315945 million kWh, which is far less than 1% of the 57,525 kWh baseline established by the market creator.
gpt-oss-20b destroys GPT-4 in a direct comparison. It's not even close. GPT-4 still occasionally struggled with primary school math. gpt-oss-20b aces competition math and programming, while performing at PHD level on GPQA (page 10 of the model card, see screenshot below):
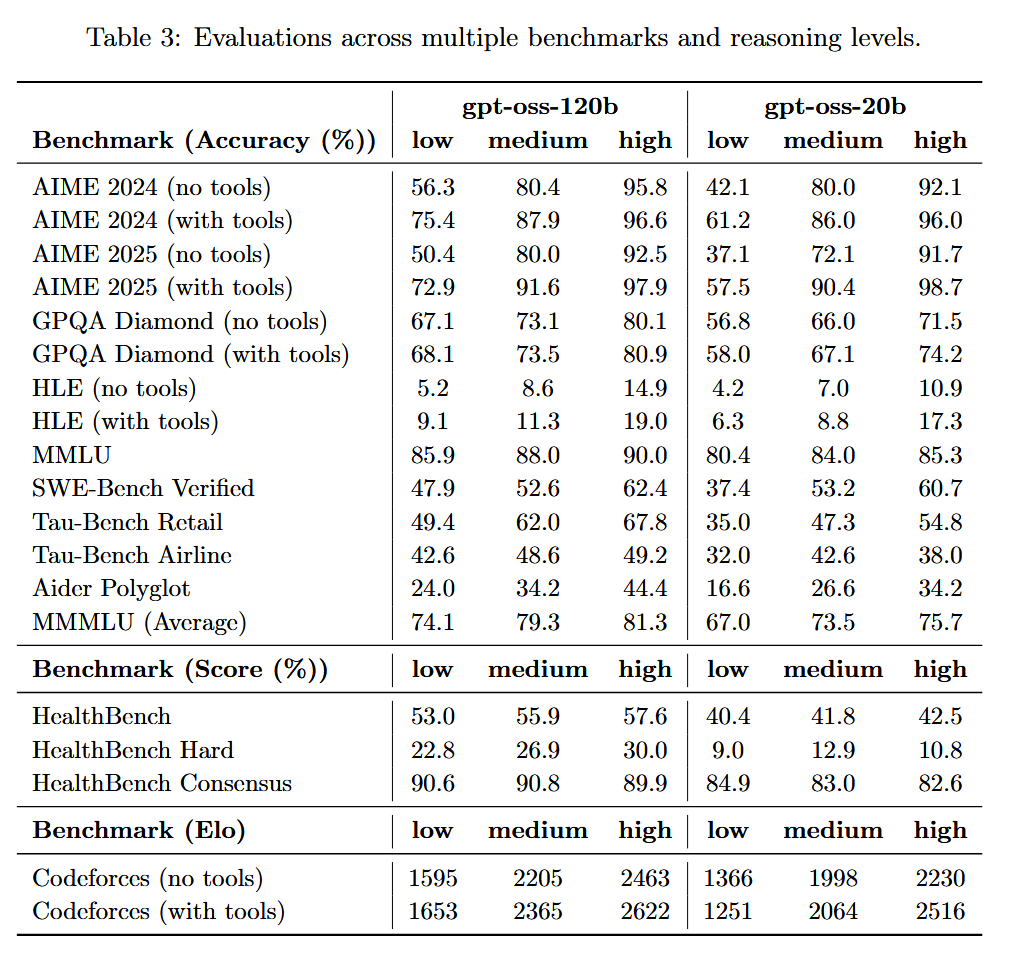
AIME 2024 (no tools)
• 20b: 92.1%
• GPT-4 (orig): ~10–15% (proxy: GPT-4o reported 12% and the 2023 GPT-4 wasn’t better on AIME-style contests). Result: 20b crushes it.
(https://openai.com/index/learning-to-reason-with-llms)AIME 2025 (no tools)
• 20b: 91.7%
• GPT-4 (orig): no reliable public number; based on AIME-2024 behavior, likely ≤20%. Result: 20b ≫ GPT-4.GPQA Diamond (no tools)
• 20b: 71.5%
• GPT-4 (orig baseline): ~39%. Result: 20b ≫ GPT-4.
(https://arxiv.org/abs/2311.12022?utm_source=chatgpt.com)MMLU (5-shot)
• 20b: 85.3%
• GPT-4 (orig): 86.4%. Result: roughly parity (GPT-4 a hair higher).
(https://arxiv.org/pdf/2303.08774)SWE-bench Verified
• 20b: 60.7%
• GPT-4 (orig): 3.4% (20b simply crushes GPT-4)
(https://openreview.net/pdf?id=VTF8yNQM66)Codeforces Elo (no tools)
• 20b: 2230 (with tools 2516)
• GPT-4 (orig): no official Elo; GPT-4o scored ~808. So original GPT-4 likely sub-1k on this setup. Result: 20b ≫ GPT-4.
(https://arxiv.org/html/2502.06807v1)
If such a model is trained on synthetic data generated with a precursor model, does this take into account the energy used to train the precursor + run inference on it to produce the synthetic data?