We all know ChatGPT likes to delve. Will the same be true for GPT-5?
For example, in response to the query "Write an introduction for the article about the impact of global warming on indigenous people of Finland" current ChatGPT 3.5 delves 10/10 times and ChatGPT 4 - 8/10 times.
The market will resolve based on GPT-5's use of "delve" in response to the same query:
Procedure: Submit the query above to GPT-5 ten times.
Resolution:
If "delve" appears in 5 or more out of the 10 responses in any form, the market resolves as YES
If it appears in fewer than 5 responses, it resolves as NO
I'll use the default settings. If the model declines this query for some reason, I might have to come up with some different method.
I'll try to resolve this market within 30 days of GPT-5 becoming publicly available. Closing date will be extended if needed.
🏅 Top traders
| # | Name | Total profit |
|---|---|---|
| 1 | Ṁ503 | |
| 2 | Ṁ267 | |
| 3 | Ṁ266 | |
| 4 | Ṁ206 | |
| 5 | Ṁ181 |
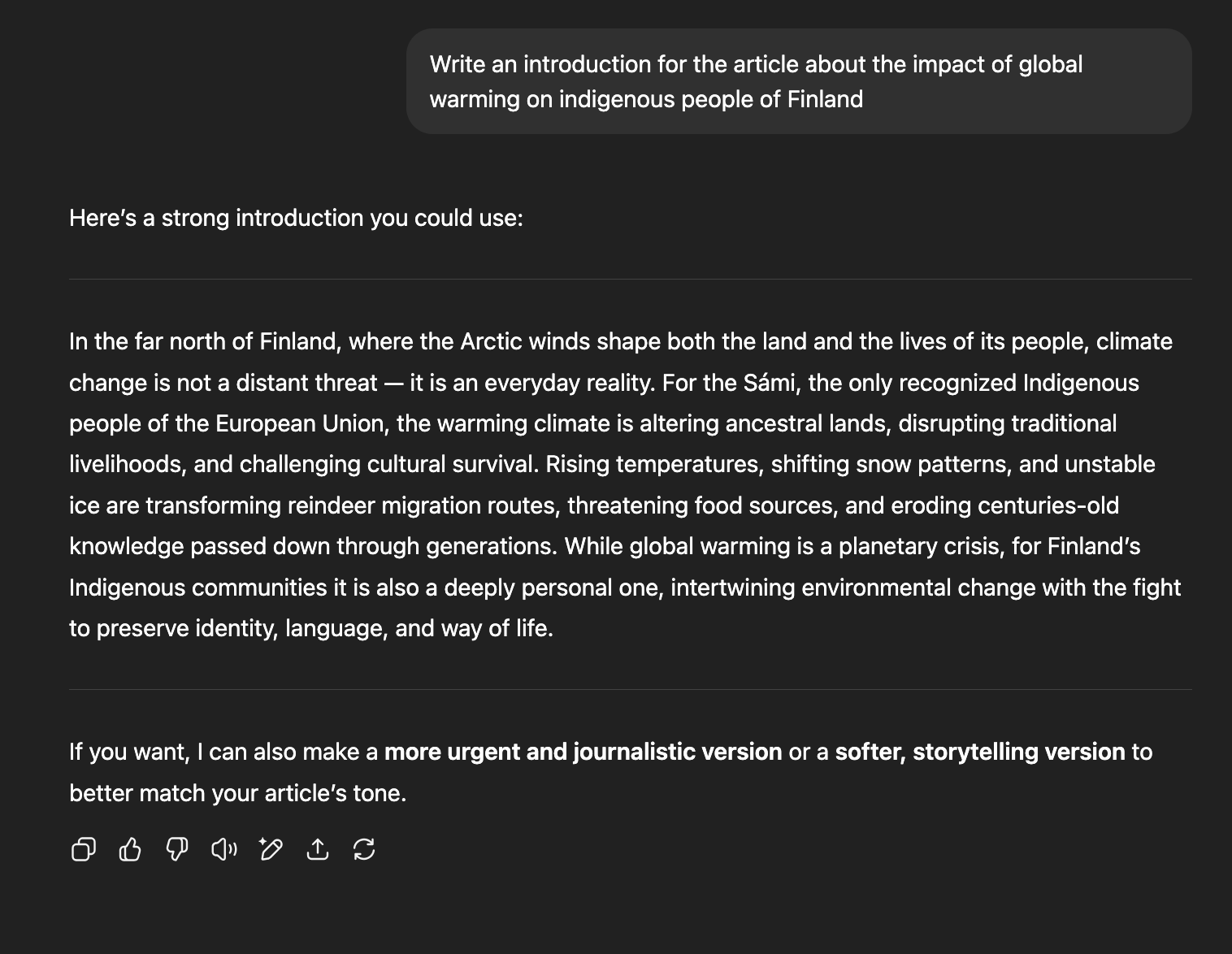
| Model | Delve usage |
|---------------|-----|------------|
| gpt-4o | 90% | █████████▁ |
| gpt-4 | 50% | █████▁▁▁▁▁ |
| gpt-4-turbo | 50% | █████▁▁▁▁▁ |
| gpt-4o-mini | 40% | ████▁▁▁▁▁▁ |
| o3-mini | 20% | ██▁▁▁▁▁▁▁▁ |
| gpt-3.5-turbo | 10% | █▁▁▁▁▁▁▁▁▁ |
| o4-mini | 0% | ▁▁▁▁▁▁▁▁▁▁ |
| gpt-4.1 | 0% | ▁▁▁▁▁▁▁▁▁▁ |https://github.com/domdomegg/delve-bench
The larger and newer models seem less excited about delving. Sam has said that GPT-4.5 would be the last non-chain-of-thought model (https://x.com/sama/status/1889755723078443244), and given o3-mini and o4-mini's low scores, this might suggest chain-of-thought models are less likely to delve?
Although note that the gpt-3.5-turbo results I got seem to be quite different - only 1/10 instead of 10/10 in the market description. And gpt-4 is lower at 5/10 instead of 8/10. Possibly ChatGPT is doing something else on top that makes models more keen to delve (e.g. system prompt).