
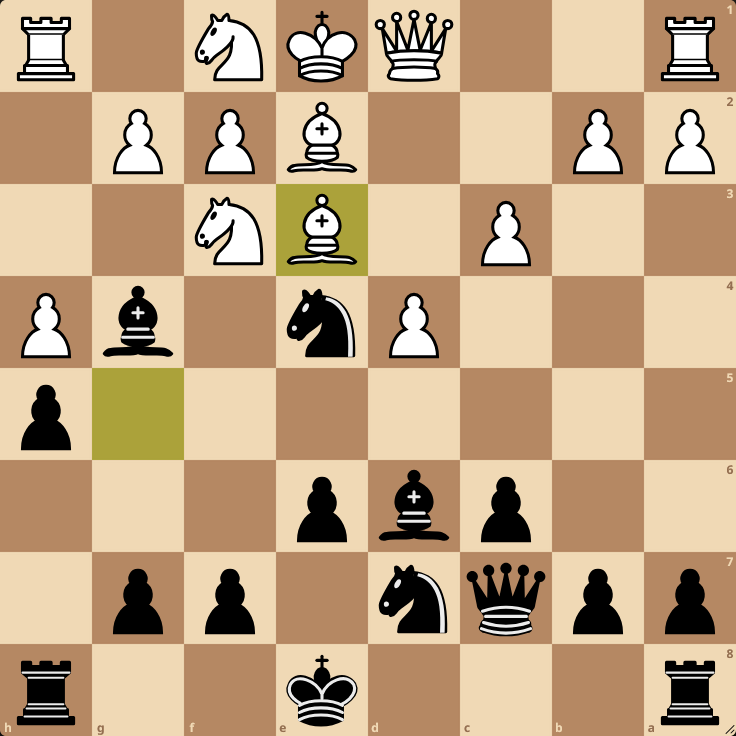
Will multi-modal AI be able to describe the state of a chessboard from an image before 2026?
The AI has to unambiguously describe the state of the board by listing/describing the location of all chess pieces.
Images will be sourced from the lichess.com 2D chessboards, about 10-30 moves into the game.
A narrow AI trained specifically for this task is excluded from this market.
The spirit of the market is about vision capability of multi-modal AI.
In the case of uncertainty / suspicion of something shady going on, I reserve the right conduct replication / resolve to the best of my judgement.
The market resolves as YES if the AI is 100% correct for 5 out of 5 images of a chessboard it has been tested on. Otherwise, it resolves as NO.
I will not bet on this market.
Example image:
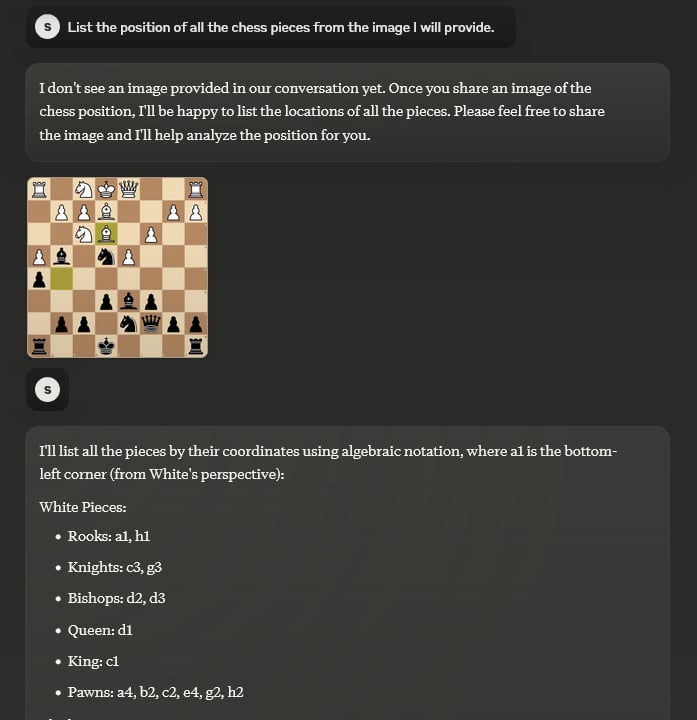
I will describe the task, then as a second step I provide the image to make the task easier for the AI given their auto-regressive nature. Prompt will look like this, each in a separate session:
Thanks for the feedback to @MrLuke255
Update 2025-10-04 (PST) (AI summary of creator comment): - No external image processing/tools: Using code (e.g., Python) to crop or split the provided image to inspect parts is not allowed.
Single-image analysis: The AI must analyze the provided lichess 2D board image as-is, without programmatic cropping or similar preprocessing.
@Metastable Thanks for the clarification. In my testing, after turning off code interpreter in my settings, GPT-5 Thinking does make some mistakes.