I'm not too concerned about o1-mini or o1-preview performing 100+ ELO better than GPT-4o because OpenAI has already released human preference data. These models only achieve a 70% win rate on math, leading to about a 75 ELO improvement—still roughly 50 ELO short of reaching 1453. Even if the full o1 model performs 50 ELO better than o1-preview, the data in the graph suggests it's unlikely to surpass 1453. I believe Orion or GPT-5 could achieve 1453+ ELO, but the market only gives that a 30% chance this year. Overall, I think the market is fairly well-calibrated at 75%, though perhaps a bit pessimistic.
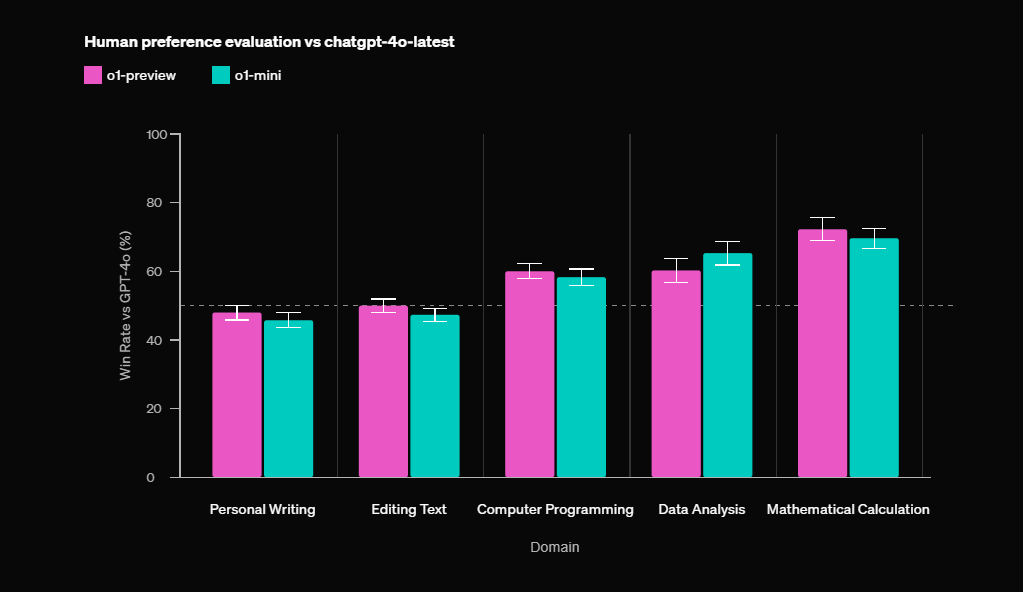
@ZinqTable The initial results for o1-preview are in, and it's only 20 elo points higher than 4o.
That is not the same statement at all.
ELO is a way to measure how much better an agent is compared to the rest of competitors, based on the results of head-to-head matches. Gary is saying that we won’t have something 200 points higher than GPT-4. Gary’s statement could be correct if a few great chatbots emerge, and GPT-4’s ELO rating drops as a result.
I'd bet no on a version of this that excluded ties and a few other things. However, I think that ties and the low quality of many questions (and the low quality of the evaluation of many answers) might mean that even enormous improvements might not be enough to get a model to 1453. We are, I think, bumping on the ceiling of this particular method of evaluation, and while a fantastic enough model probably could reach 1453, it would not be the smallish-moderate sized improvement it may appear to be at first glance.